Paginating Requests in APIs
Should all APIs use Cursor-based pagination? Learn the different pagination strategies available and their advantages and disadvantages

When exposing large data sets through APIs, it needs to provide a mechanism to paginate the list of resources. Multiple names are used in the industry for endpoints that return a paginated set, particularly in REST APIS, such as collection resource, listing endpoints, index endpoints, etc. I am going to name it “listing endpoints” throughout the document.
Although rarely, a listing endpoint is not paginated, it might happen. Mainly when the set is fixed, well defined, and the amount of data is considerably small.
Before exposing any listing endpoint, we should ask ourselves at least the following questions: Can the list be sorted? Is there any default order? Can the list be filtered? If so, which filter params should it accept? Are the queries, executed under the hood, performant enough? Exposing endpoints is very easy. Deprecating and deleting them is extremely hard and potentially impossible.

There are different techniques to provide listing endpoints and how to paginate them. In this post, I will discuss different approaches and their usage in the industry. Most use cases are REST APIs, but it applies to any SOAP, REST, GraphQL, etc. The most common pagination techniques are Page-based pagination (also called offset-based pagination), KeySet-Based pagination, and Cursor-based Pagination.
Page — based pagination
This is the simplest and most common form of paging, particularly for Apps that use SQL Databases. The set is divided into pages. The endpoint accepts a page param that is an integer indicating the page within the list to be returned.

If it’s using SQL, It will do a query using LIMIT and OFFSET, where the first is the length of the page and the latter is the number of records already returned (page's size * page).

SQL offset skips the first N results of the query. Nonetheless, the database will have to fetch the N results from the disks and bring them to return the records next to them.
“…the rows are first sorted according to the <order by clause> and then limited by dropping the number of rows specified in the <result offset clause> from the beginning…. .” SQL:2016, Part 2, §4.15.3 Derived tables
See the analysis of performance using OFFSET by Markus Winand.
Pros:
- You can jump to any particular page, not needing to query 99 pages to get the
page100. - It allows sending parallel requests with different pages.
- Stateless on the server-side.
- Easy to understand and debug.
- This approach requires very little business logic. Many libraries are written in different languages that are easy to use.
Cons:
- Bad performance for large
OFFSETin SQL. The database must scan and count N rows when doing OFFSET in SQL.
“The larger the offset, the slower the request is, up until the point that it times out.” Shopify Blog
- It can return repeated or missing if any is added/deleted while paginating. E.g., If the first request asks for page 1 and a new record is inserted to the first page, then the request with page 2 will have a record repeated which was returned on the previous request.
KeySet-based pagination
The API provides a key param that acts as a delimiter of the page. This key param should be the same key of the set sort order. For example, if the set is sorted by ID, then the key param should be since_id. Other examples would be since_updated_at, since_created_at etc.
The first request doesn’t contain the delimiter param. The response to this request will have the value of the key for the last element of the set. For instance, if the delimiter is the id, to get the next page, the client needs to send the paramsince_id with the value id of the last element of the response, and the set must be sorted by id.
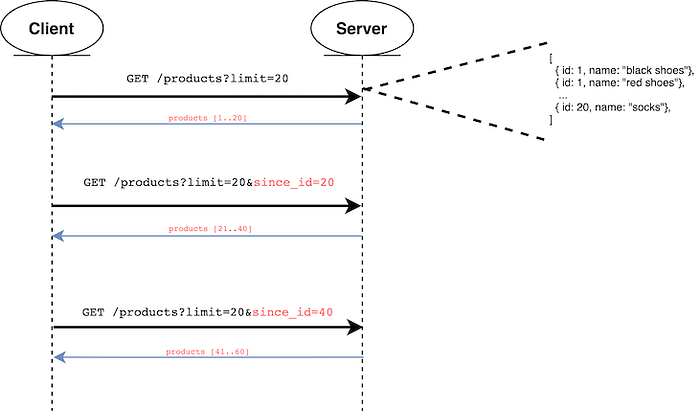
The SQL query executed would be:

Pros:
- The SQL query is more efficient than OFFSET (for most cases) since it uses a WHERE condition (assuming it has good SQL indexes).
- Unlike page-based pagination, new records inserted on previous pages won’t cause duplicated elements.
Cons:
- It’s tied to the sort order. If you want to use
since_id, the set should be sorted byid. - There is no way to jump to a specific page. It needs to iterate through all the previous pages.
- It doesn’t allow sending parallel requests for different batches.
- The API needs to expose multiple key-params (e.g.
since_id,since_updated_at). - The client needs to keep track of the key-value of the set.
- Missing items if they are added to the previous pages
Cursor-based pagination
Given a set, a cursor will be a piece of data that contains a pointer to an element and the info to get the next/previous elements. The server should return the cursor pointing to the next page in each request. In most cases, the cursor is opaque, so users cannot manipulate it.
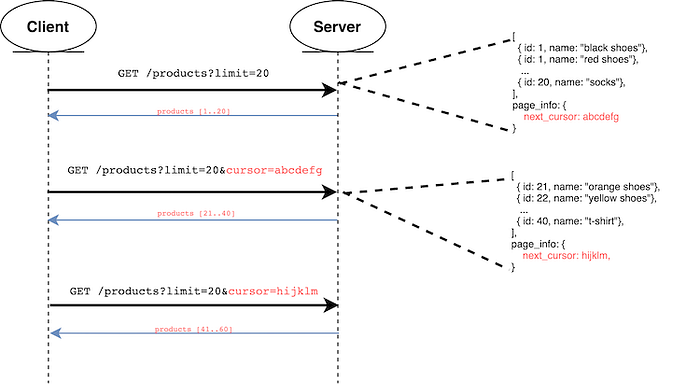
Some APIs also return a cursor per element so that clients can ask for elements after a specific one.
The SQL query will depend on the implementation, but it will be similar to the query generated by the KeySet-based Pagination method using a WHERE condition.
There are different approaches to implementing this method. Some return the cursor as part of the payload. Others return the cursor as part of the Header, particularly in the LINK headers. The cursor might contain all the information needed or partially allowing clients to add other filter parameters.
Clients should not store the cursor on their side. Google API Documentation suggests adding an expiration date to the token and expiring cursors sent in requests.
Pros:
- If the cursor is opaque, the implementation underneath can change without introducing an API change.
- In most cases, it is much faster than using page in SQL since it won’t use OFFSET in the database.
- There is no issue when a record is deleted as opposed to Page-based Pagination.
Cons:
- There is no way to skip pages. If the user wants page X, it must request pages from 1 to X.
- It doesn’t allow sending parallel requests for different batches.
- The implementation is more complex than LIMIT/OFFSET.
- Hard to debug. Given a request, you have to decode it to debug it.
- Missing items if they are added to the previous pages
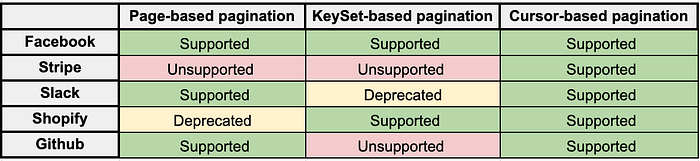
Usages in the industry
Different Apps follow different techniques. In this section, I will describe a few approaches taken by different companies:
Stripe
Stripe does use cursor-based pagination in its REST API. It accepts three parameters: limit, starting_afterand ending_before.
Both parameters take an existing object ID value and return objects in reverse chronological order. The
ending_beforeparameter returns objects listed before the named object, and thestarting_afterparameter returns objects listed after the named object. These parameters are mutually exclusive -- only one ofstarting_afterorending_beforemay be used.
Facebook:
Facebook uses the three types of pagination mentioned here, but they emphasize using Cursor-based pagination.
“Cursor-based pagination is the most efficient method of paging and should always be used when possible.” Facebook API Docs
Page-based Pagination: Accepts two params, offset and limit.
https://facebook.com/me/feed?limit=25&offset=50
Time-based Pagination: It’s a particular case of KeySet-based pagination where the key is a timestamp (e.g. created_at, updated_at). It accepts one of the two parameters (since or until). For example:
https://facebook.com/me/feed?limit=25&since=1314224121 https://facebook.com/me/feed?limit=25&until=1314224121
Cursor-based Pagination: It accepts one of the two params before or after, and the value of it is the cursor returned by previous requests. Example:
https://facebook.com/me/feed?limit=25&before=NDMyNzQy https://facebook.com/me/feed?limit=25&after=NDMyNzQy
Slack API
The Slack API uses the three methods. However, Cursor-based pagination is used heavily, and KeySet-based pagination was removed in Nov 2020.
Cursor-based pagination: It accepts cursor and limit parameters. The response returns the cursor as part of the payload to be sent in the subsequent request.
https://slack.com/api/user.list?limit=20&cursor=dXljpVEc6&token=123JOIC
Page-based pagination: It uses page and count or other limiting parameters. Only a few endpoints support it.
KeySet-based pagination: The key is a timestamp value oldest and latest. This method is deprecated.
Shopify:
Shopify uses the three methods. However, Page-based pagination is deprecated in the REST Admin API in favor of Cursor-based pagination.
Cursor-based Pagination: The response body of a GET request returns the first page of results, and the response header returns the URLs to the next and previous page (if applicable) via the LINK header.
Note: I worked on the project where we introduced Cursor-base pagination at Shopify. The performance improvement was tremendous. If you want to learn more, see this article.
Github:
Github uses page-based Pagination on version REST v3 that accepts a page param.
https://api.github.com/search/code?=addClass+user:mozilla&page=10
It was removed on version v4, which uses GraphQL and Cursor-based pagination via the params before and after.
Popular APIs pagination mechanisms
Conclusions
There isn’t any perfect solution for pagination. It depends on the case. If you don’t care about skipping pages and performance is essential for the case, I suggest using cursors; otherwise, using page might be the best option.
As an anecdote, this article was on the first page of hacker news for a few days with lots of valuable comments.
Thanks to Marius-Constantin Melemciuc, German Chiazzo, and Princejeet Singh for reviewing this post.
