Optimizing Ruby Background Jobs: Batching and Bulk Inserts
In this blog, I will describe my journey to identify and fix a time-out issue. The language and framework used are Ruby on Rails, but the lessons apply to others.
Background Job overview
Before diving into the metrics, it’s essential to understand the basics of Background jobs. They are processes that job workers run. They perform tasks that can be interrupted and resumed later (some are uninterruptible). I used the Job Iteration gem by Shopify which extends ActiveJob by making the jobs interruptible and resumable.
In your application, when you tell the job to perform_later, many things happen under the hood:An object is created that contains the Job class and the parameters, and the object is passed onto a queue (e.g., Redis). In our example, the object will look like <job_class: Job, args: { user_id: 1}>
The complexity increases as the application grows. Each worker could run on a different machine or in a different data center. There could be many workers running in parallel and many different queues. Each job worker could read from one or many queues. The architecture depends on your application and your vendor.
Debugging a slow background Job
Looking at the code of the background job that was timing out, it seems very simple.
class CarUserCreateInBulkJob < ActiveJob
def perform(car, user_ids)
# ... some validations
user_ids do |user_id|
CarUser.create(user)
end
end
endMy first step was to look for observability. All I knew was that the job was timing out in some scenarios.
Logging background jobs
I added logging to the job; I kept track of different metrics such as processing time, I/O time, interruptions, retries, etc.
The processing time logs the total time the job takes without counting retries. P50 was ok, however, p95 and p99 of the processing time were quite high. This was a red flag.
The issue
I grabbed some samples to analyze its trace and saw the following:
[ActiveJob] Performing CarUserCreateInBulkJob
[SQL QUERY] SELECT * FROM cars WHERE ID in (....)
[SQL QUERY] SELECT * FROM users WHERE ID in (....)
[SQL QUERY] INSERT INTO car_users (car_id, user_id) VALUES .....
[ActiveJob] Enqueued CarReportJob
[ActiveJob] Failed Enqueuing CarReportJob
[ActiveJob] Failed Enqueuing CarReportJob
[ActiveJob] Failed Enqueuing CarReportJob
[ActiveJob] Failed Enqueuing CarReportJob
# ..... many more failed enqueuing logs.
# [ActiveJob] finished CarUserCreateInBulkJob.As you can see, the job CarUserCreateInBulk started performing. Some SQL queries were executed, and another job CarReportJob attempted to be enqueued many times but failed. This was a red flag! I looked at the models and noticed that the CarReportJob was enqueued in the after_commit callback for the CarUser model.
class CarUser
after_commit: fire_report_job
private
def fire_report_job
CarReportJob.perform_later(car_id)
end
endEureka! Whenever we create an entry in CarUser, we enqueue one CarReportJob and the CarUserCreateInBulkJob creates many CarUsers.
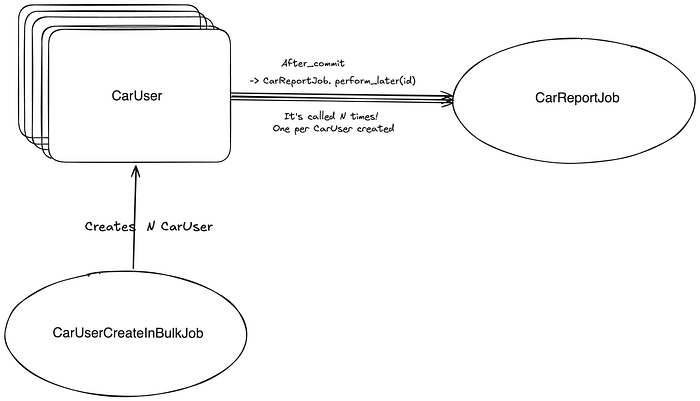
Solution
There are many solutions to this problem, but all are based on batching the jobs.
Instead of enqueuing CarReportJob every time a CarUser is created, we can batch the jobs and enqueue them at the end of CarUserCreateInBulkJob at once. The result can be seen below:

The implementation
For that, I used an in-memory cache, with car_id as the key, that keeps track of the car_ids that are going to be inserted within the thread, like the following example:
# The Batcher is a singleton class that uses a Set to keep track of the car_ids to be used by CarReportJob.
class CarReportJobBatcher
class << self
def batch(element)
instance.set.add(car_id:)
end
def perform(car_id:)
return if instance.set.include?(car_id)
CarReportJob.perform_later(car_id)
end
def perform_all_later
jobs = instance.set.map do |car_id|
CarReportJob.new(car_id)
end
ActiveJob.perform_all_later(jobs) # performs a single roundtrip to the job's queue
instance.set.clear
end
def instance
@instance ||= new
end
end
attr_reader :set
def initialize
@set = Set.new
end
private_class_method :initialize
endA CarReportJobBatcher class would store an in-memorySet with the car_ids to be run. The caller (CarUserCreateInBulkJob) will call CarReportJobBatcher#batch many times and a final call to CarReportJobBatcher#perform_all_later at the end like the following piece of code.
class CarUserCreateInBulkJob < ActiveJob
def process
# ... some validations
user_ids.each do |user_id|
CarReportJobBatcher.batch(car_id: car_id)
CarUser.create(user)
end
#...
CarReportJobBatcher.perform_all_later!
end
end
class CarUser
after_commit: fire_report_job
private
def fire_report_job
CarReportJobBatcher.perform(car_id)
end
endNote that we still want the job to be called in after_commit, since CarUser can be created outside CarUserCreateInBulkJob.
It’s important to mention that CarReportJobBatcher.perform_all_later method uses ActiveJob#perform_all_later, which makes a single roundtrip to Redis to enqueue all the jobs (or the queue system you are using). This is much more efficient than enqueuing one job at a time in multiple Redis roundtrips.
This problem applies to other areas outside Jobs. For example, if you have a service that bulk inserts rows and the model has an after_hook commit, The callback will be executed for each object created.
Conclusion
- Ensure you have the proper monitoring tools to understand the performance of your background jobs. Measuring Latency and throughput is critical.
- There are many solutions to the problem of enqueuing jobs in a loop. The best solution depends on the context. Here, I showed one example.
- Jobs can get very complicated when you have multiple jobs depending on each other and multiple web workers and job workers.
Thanks to Alex Watt, Rob Cardy and Delta Pham for reviewing the post.
